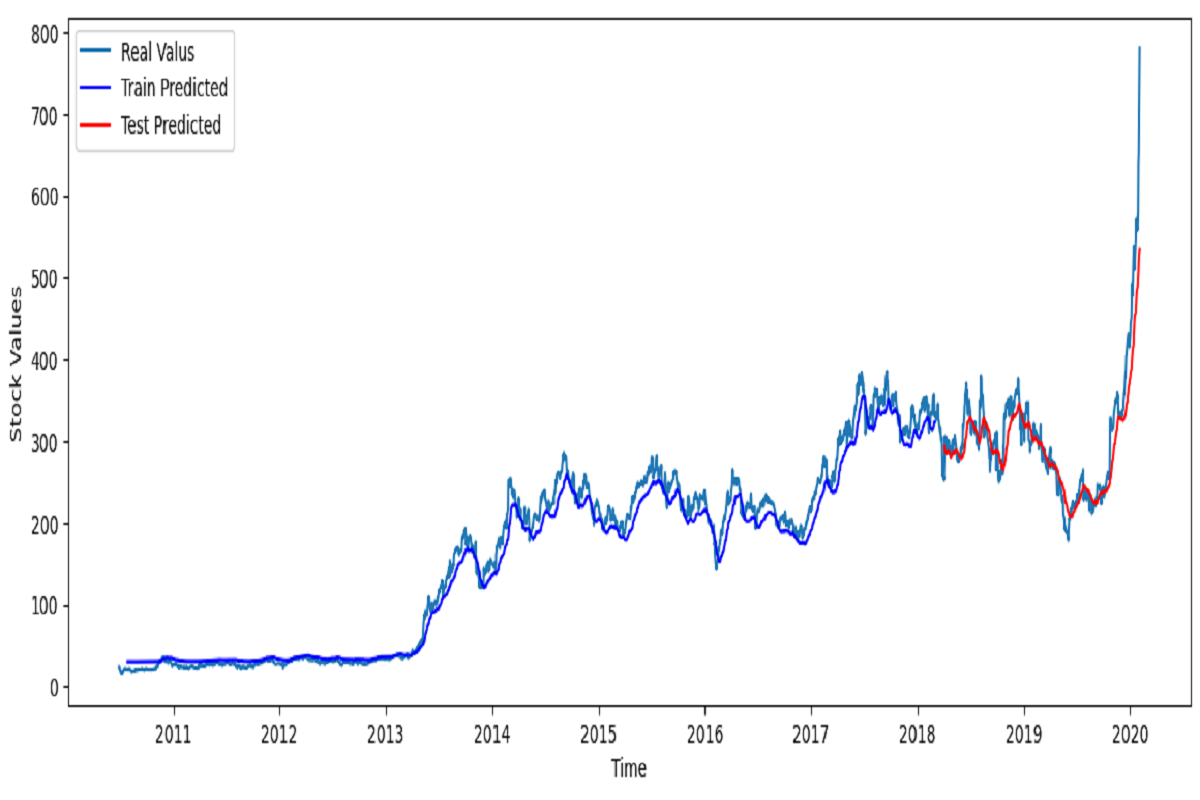
Apache vs The Fraudster
Hadoop file distribution system was set up on the Linux operating system, datasets were organized using Hive, and logistic regression and random forest models were trained using different versions of the Spark library. Significant differences in model performance were observed between different Spark versions. Ultimately, a successful fraud detection model was developed using the Random Forest algorithm, achieving 78.8% recall and 90.0% precision.

Cat-Dog Classifier App
Different models were developed by applying fine-tuning to the pre-trained VGG16, MobileNet, and ResNet50 models. The models were tracked using MLflow based on model performance, model size, different epoch counts, and training time. Ultimately, the VGG16 model was preferred with an accuracy of 97.14%. Rapid prototyping was performed using Streamlit with the developed model.

Cite Me if You Can
A semantic search and summarization tool for scientific literature. Uploaded chunked articles are semantically searched via SPECTER2 embeddings and summarized by Gemini 2.5 Flash model with proper citations in markdown and popular academic styles.

Bank Credit Risk Prediction
A successful customer risk assessment method was developed. The customer dataset was enriched and prepared for model optimization by applying data cleaning, data structuring, and feature engineering. Using the processed dataset and a deep learning algorithm, a credit risk prediction model was trained, achieving a recall of 99.5% and an F1 score of 62.5%.

Digit Recognition with AI
This project developed a basic Artificial Neural Network (ANN) to classify handwritten digits from the MNIST dataset (28x28 grayscale images of 0-9). Trained with the Adam optimizer and categorical cross-entropy loss, the model achieved 97.7% test accuracy, 98.0% precision, and 97.6% recall, demonstrating strong performance despite its simplicity. The results validate ANNs as effective tools for basic image recognition tasks.
Experimental Study
This study resulted as scaling enhances performance and consistency, deeper architectures reduce training duration and variability, while more epochs improve accuracy at a computational cost. The results emphasize balancing architectural complexity, normalization, and resource allocation for efficient model optimization.